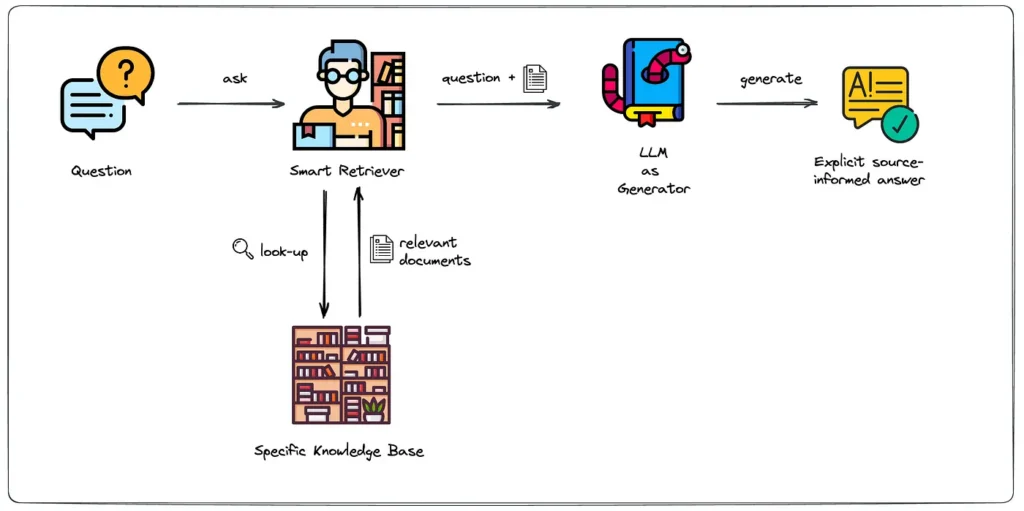
Retrieval-Augmented Generation (RAG), büyük dil modellerinin (LLM’lerin) dışarıdan yeni bilgi getirip yanıtlarına ekleme yapmasını sağlayan bir tekniktir. 2020’de ilk kez tanımlanan bu yöntem, LLM’lerin eğitim verisinde bulunmayan güncel veya uzmanlık gerektiren bilgileri dış kaynaklardan çekerek kullanmasına imkân tanır. RAG’nin temel amacı, bilgi kesintilerini kapatmak ve modelin “üretken halüsinasyon” üretme riskini azaltmaktır. Örneğin bir sohbet botu, RAG sayesinde şirket içi dokümanlar veya güncel veritabanlarından çektiği gerçek bilgileri kullanarak cevaplar üretir ve böylece yanlış veya uydurma içerik verme olasılığı azalır. RAG uygulanan sistemlerde, model yanıtlarında kaynak gösterme de mümkün olduğundan, kullanıcılar doğruluğu bağımsız olarak kontrol edebilir. Özetle, RAG LLM’leri dış veritabanlarıyla “besleyerek” onların kesitmiş bilgileri güncellemesine ve doğruluklarını artırmasına yardımcı olur.
RAG Mimarisinin Adım Adım İşleyişi
Geleneksel bir RAG sistemi dört ana adımdan oluşur: (1) Veri Hazırlama (Ingestion), (2) Bilgi Çekme (Retrieval), (3) Bağlama (Augmentation) ve (4) Yanıt Üretimi (Generation). Öncelikle referans verileri (dokümanlar, makaleler, şirket içi yazışmalar vb.) küçük parçalara bölünerek (chunking) bilgisayarın anlayacağı sayısal vektörlere (gömme vektörleri) dönüştürülür. Bu vektörler bir vektör veritabanında saklanır. Kullanıcıdan gelen bir sorgu geldiğinde, sistem sorguyu da vektöre çevirerek benzerlik araması yapar ve veri tabanından en ilgili parçaları bulur (retrieval). Sonra bu seçilen içerikler ile orijinal sorgu birleştirilir; yani modelin girişine ek bilgi (“bağlam”) olarak eklenir. Örneğin modele “Soru: …, Bağlam: …” şeklinde bir girdi oluşturulur. Böylece LLM, sadece kendi eğitimindeki bilgilere değil, getirilmiş gerçek bilgilere de bakarak cevap üretir. Son adımda, LLM bu zenginleştirilmiş girdiden yola çıkarak yanıt oluşturur. Bazı RAG uygulamaları, alınan belgeleri daha doğru sıraya koymak için yeniden sıralama (reranking) veya bağlam seçimini iyileştirmek için ek ön işlem adımları da uygular. Özetle, RAG’da önce veri gömülür ve indexlenir, ardından sorgu benzerlik aramasıyla ilgili içerikler çekilip modele verilir, model de bu gerçekçi bağlamı kullanarak cevap üretir.
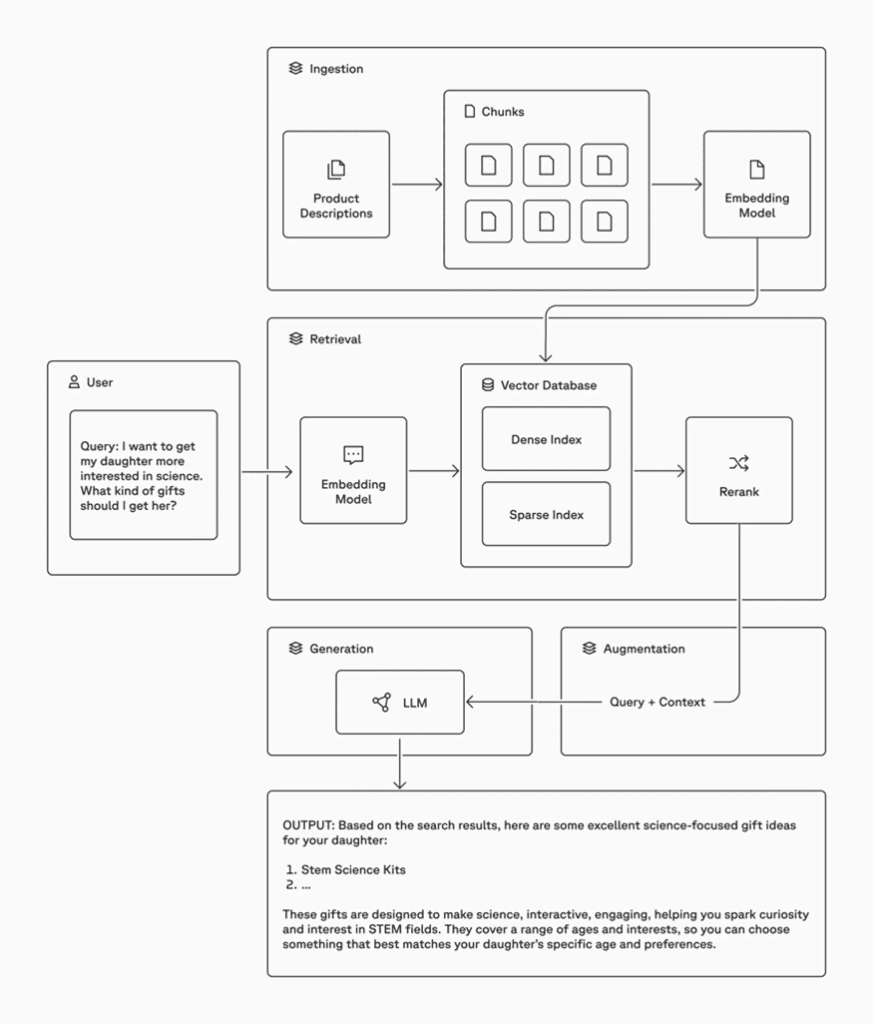
Öncelikle referans verileri (dokümanlar, makaleler, şirket içi yazışmalar vb.) küçük parçalara bölünerek (“chunking”) bilgisayarın anlayacağı sayısal gömme vektörlerine dönüştürülür. Bu vektörler bir vektör veritabanında saklanır. Kullanıcıdan bir sorgu geldiğinde, sorgu da vektöre dönüştürülerek benzerlik araması yapılır ve veri tabanından en ilgili parçalar bulunur.
Ardından bu seçilen içerikler ile orijinal sorgu birleştirilir; yani modele ek bilgi (“bağlam”) olarak sunulur. Böylece LLM yalnızca kendi eğitimindeki verilere değil, geri getirilen gerçek bilgilere de bakarak cevap üretir.
Bazı sistemlerde yeniden sıralama (reranking) gibi ek optimizasyon adımları da uygulanır.
RAG vs. İnce Ayar (Fine-Tuning) ve İstem Mühendisliği (Prompt Engineering)
Farklı optimizasyon yöntemleri arasında seçim, kullanım amacına ve maliyet faktörlerine bağlıdır. Genel olarak:
- İstem Mühendisliği (Prompt Engineering): Kısa vadede en düşük altyapı yatırımını gerektirir. Yalnızca hazır modeli nasıl sormanız gerektiğini dikkatle belirlemekle ilgilidir. Başlangıçta ücretsizmiş gibi görünür; ancak karmaşık uygulamalarda uzun ve çok kurallı girdiler (promptlar) geliştirmeniz gerekebilir. Promptlar çok uzun hale geldikçe modelin işlem süresi artar ve bakım yükü yükselir. Yani prompt yöntemi, fikir kanıtı veya erken aşama ürünlerde maliyet-etkin olsa da, ölçek büyüdükçe ek karmaşıklık getirir.
- İnce Ayar (Fine-Tuning): Mevcut bir LLM’i özel veriyle yeniden eğitmeyi içerir. En büyük maliyet ise hesaplama ve veri hazırlama yüküdür. Veri toplama, temizleme ve çok güçlü GPU’lar gerektiren eğitim, başlangıçta çok pahalıdır. Ayrıca alan geliştikçe veya kurallarda değişiklik oldukça modeli yeniden eğitmek gerekir; bu da bakım yükünü artırır. İnce ayarlı model genellikle belirli bir görevde en yüksek tutarlılığı sunar, ancak bu tutarlılık için ciddi yatırım yapmak gerekir. Ayrıca, ince ayar sürecinde düşük kaliteli veya yanlı veriler kullanılırsa hatalar modele gömülebilir; hatalı veriyi düzeltmek yeniden eğitim gerektirebilir.
- RAG (Retrieval-Augmented Generation): Temel olarak bir LLM’i doğrudan yeniden eğitmek yerine dış kaynaklardan anlık bilgi çekmeyi otomatikleştirir. RAG’ın altyapı maliyeti vardır: gömme üretimi, vektör veritabanı depolaması, sorgu araması, gecikme optimizasyonu gibi bileşenler için ödeme yapmak gerekir. Ancak bilgi tabanını güncellemek için modeli yeniden eğitmek gerekmez, bu uzun vadede maliyet tasarrufu sağlar. RAG uygulaması mühendislik olarak daha karmaşıktır; veri parçalama, arama parametreleri ve değerlendirme süreçlerini yönetebilecek uzmanlar gerektirir. Genel olarak, RAG dinamik bilgi ortamlarında esnek bir yaklaşımdır; özellikle güncel ve doğru bilgiye ihtiyaç duyulan müşteri hizmetleri chatbot’ları gibi senaryolarda tercih edilir.
Karşılaştırma özetle: Kısa vadede hızlı prototipleme için istem mühendisliği uygundur; istikrarlı, tek görevli uygulamalarda ince ayar doğru tercih olabilir; sık güncellenen veya doğruluk kritik senaryolarda ise RAG uzun vadeli verimlilik sunar.
RAG’nin Gerçek Dünya Uygulamaları
RAG, çeşitli sektörlerdeki gerçek dünya çözümlerinde kullanılmaktadır:
- Kurumsal Doküman Yönetimi: Şirket içi belgelerin ve verilerin aranmasını kolaylaştırır. Örneğin Siemens, kurumsal bilgi yönetimini geliştirmek için RAG teknolojisi kullanır; çalışanlar çeşitli dahili doküman ve veritabanlarından bilgi çekerek sorularına anında yanıtlar alabiliyor. Benzer şekilde Bell şirketi, politika ve iç belgeleri indeksleyerek çalışanların güncel bilgilere hızlıca erişmesini sağlıyor.
- Müşteri Hizmetleri Chatbot’ları: Müşteri sorularını yanıtlarken ilgili geçmiş görüşmeleri, ürün kılavuzlarını veya SSS’leri geri getirir. Örneğin Shopify’ın Sidekick adlı destek botu, RAG ile ürün bilgileri ve hesap sorunları hakkında doğru bilgi sunuyor. DoorDash da RAG tabanlı bir sistemle sürücülerine (Dasher’lar) hızlı destek sağlıyor; sorunu özetleyip ilgili dokümanları getirerek yanıt veriyor.
- Hukuk: Hukuk alanında RAG, büyük doküman yığınından ihtilaflı bilgileri çıkarmada kullanılır. Thomson Reuters’in Westlaw CoCounsel gibi ürünleri, hukuk kaynaklarına özel olarak RAG kullanıyor; böylece avukatlara güvenilir, spesifik bilgi erişimi sağlıyor. Uzmanlaştırılmış RAG çözümleri, hukuk asistanlarının kararlar için birden fazla kaynaktan doğrulanmış bilgi sunmasına olanak tanır.
- Tıp ve Sağlık: Tıp alanında RAG, klinik karar destek sistemlerinde doktorlara güncel araştırma, rehber dokümanları ve hasta verilerini bir arada sunar. Örneğin Mayo Clinic, hasta değerlendirmesi sırasında doktorlara kritik bilgileri anında getiren RAG destekli sistemler geliştiriyor. Ayrıca akademik çalışmalarda GPT-4 gibi modeller, RAG ile geliştirilen sistemlere dönüştürülerek farklı teşhis önerilerinde ve klinik araştırma süzgeçlerinde başarı göstermiştir.
- Finans: Bankacılık ve sigortacılıkta analistler için güncel raporlar ve iç kaynaklar hızlıca getiriliyor. Örneğin Allianz Bank Italy, RAG uygulamasıyla müşteri danışmalarında ilgili mevzuat ve verileri aynı anda çekerek doğruluk ve hız kazanıyor. NatWest ise RAG’li asistan “Marge” ile müşteri ve dahili ekiplere daha hızlı, doğru yanıtlar veriyor.
Bu örnekler, RAG’in kurumsal bilgi erişimi, müşteri hizmetleri ve uzmanlık gerektiren alanlarda güvenilirlik ve verimlilik sağladığını göstermektedir.
RAG Sistemlerinde Karşılaşılan Zorluklar ve Sınırlamalar
RAG güçlü olsa da uygulamada bir dizi teknik ve operasyonel zorluk vardır:
- Veri Güvenliği ve Gizlilik: RAG genellikle şirket içi veya hassas verilerle çalışır. Bu nedenle vektör veritabanları şifrelenmeli ve erişim kontrolleri uygulanmalıdır. Kullanıcılar sadece yetkili oldukları verilere erişebilmeli, aksi takdirde gizlilik ihlali riski vardır. Ayrıca prompt enjeksiyonu gibi saldırılara karşı önlem almak gerekir. Özellikle finans, sağlık ve hukuk gibi regülasyonlu alanlarda veri segmentasyonu, kimlik gizleme (anonimleştirme) ve detaylı denetim günlükleri kritik önemdedir.
- Performans Darboğazları: RAG hattı birden fazla aşamadan oluştuğundan (embed oluşturma, benzerlik araması, yeniden sıralama, uzun promptlarla üretim), her bir adım yanıt süresini uzatabilir. Büyük veri kümelerinde benzerlik araması yüzlerce milisaniye alabilir, model ise uzun bağlamları işlerken daha fazla hesaplama gücü harcar. Bu nedenle uygun önbellekleme, indeksi parçalara ayırma (sharding) ve sistem optimizasyonu yapılmalıdır. Aksi halde kullanıcılar cevapların yavaş geldiğini düşünebilir.
- Teknik Karmaşıklık ve Hata Ayıklama: RAG sisteminde hatalar, modelin mantıksal cevap vermemesine değil, genellikle çeşitli bileşenlerin uyumsuzluğundan kaynaklanır. Örneğin yanlış doküman dönen bir retriever, modelin tutarsız cevaplar üretmesine yol açabilir. Hatanın kaynağını belirlemek zor olduğu için, her aşama izlenmeli: hangi dokümanlar çekildi, nasıl sıralandı, model bunları nasıl kullandı gibi. Eksik veya hatalı indeksleme veri kalitesini düşürür. Ayrıca altyapı karmaşıklığı (v. veritabanları, retriever servisleri, LLM servisleri vs.) geliştirme ve yönetim yükünü artırır.
Bu zorluklar nedeniyle RAG uygulaması tasarlarken veri yönetimi, güvenlik, performans izleme ve detaylı testlere özel önem verilmelidir.
İleri Düzey RAG Teknikleri ve Yenilikler (2026)
Geleneksel RAG’in sınırlarını aşmak için son dönemde bir dizi güncel teknik geliştirilmiştir. Bunlar arasında şunlar öne çıkar:
- Yeniden Sıralama (Reranking): İlk çekilen belgeler, daha hassas bir modele (örneğin cross-encoder) veya özelleştirilmiş sıralama servisine gönderilerek en uygun ilk k öğe seçilir. Reranking, basit vektör aramalarının hatalı sıralamalarını düzeltir ve LLM’e daha doğru bağlam sunar.
- Hibrit Arama (Yoğun + Seyrek): Geleneksel vektör aramaya ek olarak anahtar kelime araması (BM25 gibi) da yapılır. İki arama sonucu birleştirilerek hem anlamsal benzerlik hem anahtar terim eşleşmesi sağlanır. Böylece nadir terimler veya kod isimleri gibi bilgi atlanmaz.
- Sorgu Genişletme ve HyDE: Kullanıcının sorusu, eşanlamlılar veya ilgili terimler eklenerek genişletilir. Örneğin “fetch” yerine “get, retrieve” gibi kelimeler eklenir. HyDE (Hypothetical Document Embeddings) gibi yaklaşımlarda, veri parçası bazında modelden beklenen cevaba benzer bir metin üretilip bu örnek dokümanlardan arama yapılır. Bu yöntemler, soru ile dokümanlar arasındaki dil farkını kapatır ve doğru belgenin bulunmasını kolaylaştırır.
- Bağlam Optimizasyonu (Özetleme/Yoğunlaştırma): Büyük doküman parçaları doğrudan modele verilmek yerine, odaklı özetler çıkarılır. Örneğin GraphRAG, sorguya özel özetleme ile yalnızca ilgili bilgiyi uzun bağlam sınırı içerisinde tutar. LangChain ve LlamaIndex gibi araçlar, bağlamın özetlenmesi veya yığılmasının (compression) uygulanmasını destekler. Böylece LLM’e verilen bağlam daha kompakt ve alakalı olur, dikkat dağınıklığı azalır.
- Bilgi Grafiği Tabanlı RAG (GraphRAG): Dokümanlarda kişi, ürün, dava gibi varlıklar ile aralarındaki ilişkiler çıkarılarak bir bilgi grafiği oluşturulur. Sorgularda bu graf üzerinde gezerek çok adımlı ilişkili bilgi toplanır. GraphRAG, ilişkisel verileri dikkate alarak çoklu atlamalı soruları daha iyi yanıtlar ve kaynak izlenebilirliğini artırır. Örneğin bir yasal soru çözerken, ilgili yasa maddeleri ve emsal davaların grafik bağlantıları üzerinden çekilebilir.
- Çok Adımlı Akıl Yürütme (Agentik Planlama): Kompleks sorular için otomatik planlayıcı ajanlar kullanılır. Soru daha küçük parçalara bölünür, her parça için en uygun geri getirme aracı (graf sorgusu, hibrit arama vs.) seçilir ve sonuçlar birleştirilir. Zincirleme düşünce (Chain-of-Thought) yöntemleriyle model adım adım cevap oluşturur, her aşamada elde edilen kanıtlar kontrol edilir. Bu, kapsamı geniş sorularda kaçan noktaları yakalamaya ve uydurma cevapları azaltmaya yardımcı olur.
Bu tekniklerin tümü, RAG sistemlerini daha doğru, kapsamlı ve güvenilir hale getirir. Güncel literatürde Advanced RAG kapsamında yeniden sıralama, hibrit arama, sorgu optimizasyonu, bağlam yoğunlaştırma, bilgi grafiği entegrasyonu gibi yöntemler sıkça kullanılmaktadır.
Retrieval-Augmented Generation (RAG), LLM’lerin güncel ve uzmanlık gerektiren bilgileri kullanarak daha doğru yanıtlar üretmesini sağlar. Bu makalede RAG’nin temellerinden başlayarak mimari işleyişini, prompt/fine-tuning karşılaştırmalarını, gerçek dünya uygulamalarını ve gelişmiş teknikleri ele aldık. Sonuç olarak, RAG çözümleri doğru veri kaynakları ve iyi tasarlanmış bir altyapı ile birleştirildiğinde, kurumların bilgiye erişimini hızlandırır ve LLM’lerin güvenilirliğini artırır. Ancak bu sistemlerin başarılı olabilmesi için veri güvenliği, performans ve kalite kontrolüne dikkat edilmesi gerekir. İleri RAG teknikleri ile geleneksel RAG sınırları aşılmakta, daha karmaşık sorular bile doğru şekilde cevaplandırılabilmektedir. Yeni nesil RAG yaklaşımları, önümüzdeki yıllarda LLM uygulamalarının temel yapı taşlarından biri olmaya devam edecektir.
Kaynaklar
https://en.wikipedia.org/wiki/Retrieval-augmented_generation
https://www.pinecone.io/learn/retrieval-augmented-generation/
https://medium.com/@ieltswithnayeem/the-real-cost-of-rag-vs-fine-tuning-vs-prompt-engineering-its-not-what-you-think-f612c4f41349
https://www.ibm.com/think/topics/rag-vs-fine-tuning-vs-prompt-engineering
https://www.ema.ai/additional-blogs/addition-blogs/retrieval-augmented-generation-use-cases
https://legal.thomsonreuters.com/blog/retrieval-augmented-generation-in-legal-tech/
https://pmc.ncbi.nlm.nih.gov/articles/PMC12059965/
https://www.techtarget.com/searchenterpriseai/tip/Understanding-the-limitations-and-challenges-of-RAG-systems
https://neo4j.com/blog/genai/advanced-rag-techniques/
Bora Kurum sitesinden daha fazla şey keşfedin
Subscribe to get the latest posts sent to your email.